



You can tell search engines which pages to crawl by writing a robots.txt file. You can also prevent search engines from crawling and indexing specific pages, folders, your entire site, or your webflow.io subdomain. This is useful for hiding pages like your site’s 404 page from being indexed and listed in search results.
Important: Content from your site may still be indexed, even if it hasn’t been crawled. That happens when a search engine knows about your content either because it was published previously, or there’s a link to that content from other content online. To ensure that a previously indexed page is not indexed, don’t add it in the robots.txt. Instead, use the noindex meta code to remove that content from Google’s index.
In this lesson:
- How to disable indexing of the Webflow subdomain
- How to generate a robots.txt file
- Best practices for privacy
- FAQ and troubleshooting tips
How to disable indexing of the Webflow subdomain
You can prevent Google and other search engines from indexing your site’s webflow.io subdomain by disabling indexing from your Site settings.
- Go to Site settings > SEO tab > Indexing section
- Set Disable Webflow subdomain indexing to “Yes”
- Click Save changes and publish your site
This will publish a unique robots.txt only on the subdomain, telling search engines to ignore this domain.
Note: You’ll need a Site plan or paid Workspace to disable search engine indexing of the Webflow subdomain. Learn more about Site and Workspace plans.
How to generate a robots.txt file
The robots.txt is usually used to list the URLs on a site that you don't want search engines to crawl. You can also include the sitemap of your site in your robots.txt file to tell search engine crawlers which content they should crawl.
Just like a sitemap, the robots.txt file lives in the top-level directory of your domain. Webflow will generate the /robots.txt file for your site once you create it in your Site settings.
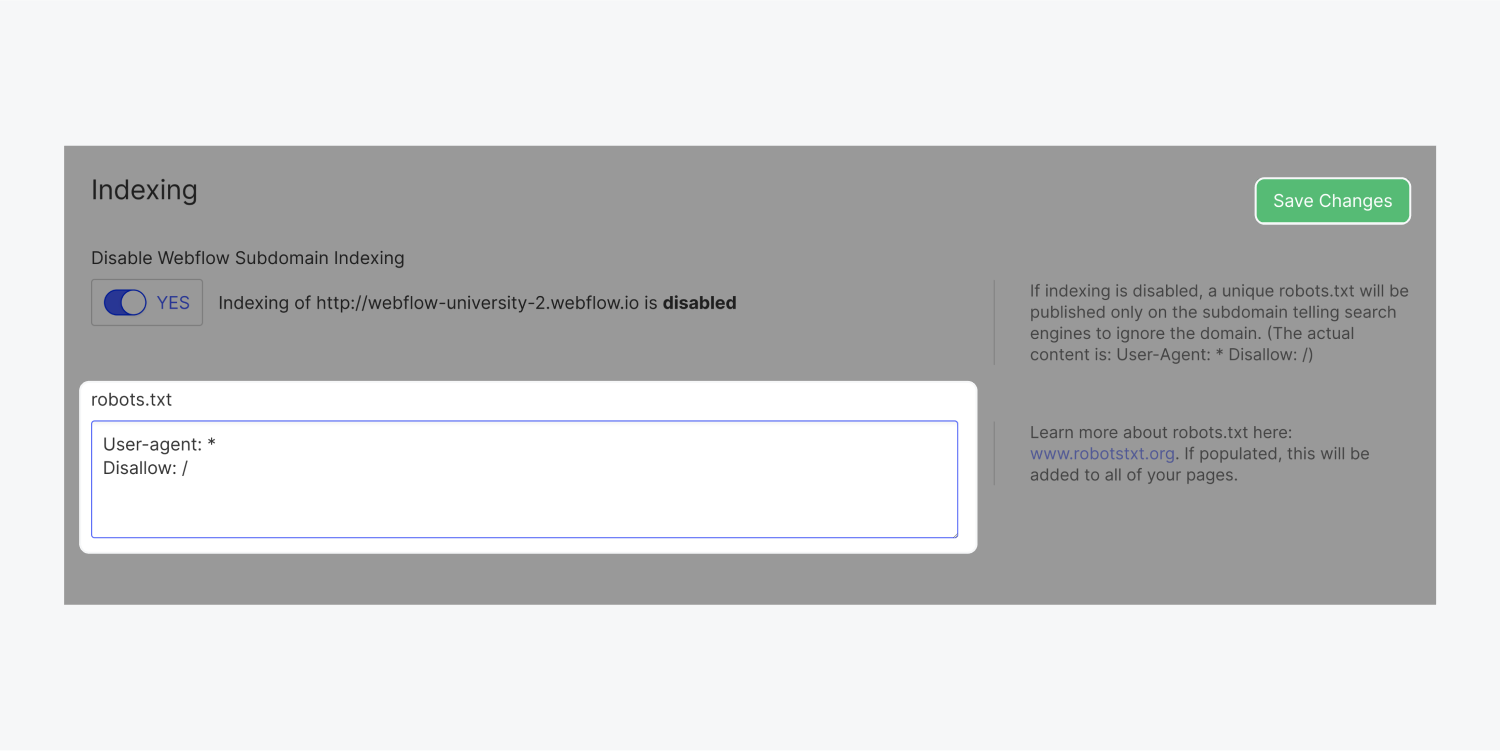
To create a robots.txt file:
- Go to Site settings > SEO tab > Indexing section
- Add the robots.txt rule(s) you want
- Click Save changes and publish your site
Important: Content from your site may still be indexed, even if it hasn’t been crawled. That happens when a search engine knows about your content either because it was published previously, or there’s a link to that content from other content online. To ensure that a previously indexed page is not indexed, don’t add it in the robots.txt. Instead, use the noindex meta code to remove that content from Google’s index.
Robots.txt rules
You can use any of these rules to populate the robots.txt file.
- User-agent: * means this section applies to all robots.
- Disallow: tells the robot to not visit the site, page, or folder.
To hide your entire site
User-agent: *
Disallow: /
To hide individual pages
User-agent: *
Disallow: /page-name
To hide an entire folder of pages
User-agent: *
Disallow: /folder-name/
To include a sitemap
Sitemap: https://your-site.com/sitemap.xml
Helpful resources
Check out more useful robots.txt rules.
Note: Anyone can access your site’s robots.txt file, so they may be able to identify and access your private content.
Best practices for privacy
If you’d like to prevent the discovery of a particular page or URL on your site, don’t use the robots.txt to disallow the URL from being crawled. Instead, use either of the following options:
- Use the noindex meta code to disallow search engines from indexing your content and remove content from search engines’ index.
- Save pages with sensitive content as draft and don’t publish them. Password protect pages that you need to publish.
FAQ and troubleshooting tips
Can I use a robots.txt file to prevent my Webflow site assets from being indexed?
It’s not possible to use a robots.txt file to prevent Webflow site assets from being indexed because a robots.txt file must live on the same domain as the content it applies to (in this case, where the assets are served). Webflow serves assets from our global CDN, rather than from the custom domain where the robots.txt file lives.
I removed the robots.txt file from my Site settings, but it still shows up on my published site. How can I fix this?
Once the robots.txt has been made, it can’t be completely removed. However, you can replace it with new rules to allow the site to be crawled, e.g.:
User-agent: *
Disallow:
Make sure to save your changes and republish your site. If the issue persists and you still see the old robots.txt rules on your published site, please contact customer support.
